


 4008-622-911
4008-622-911





INTEL英特爾發(fā)布第六代至強(qiáng)SP處理器:將小芯片設(shè)計(jì)進(jìn)行到底英特爾發(fā)布第六代至強(qiáng)SP處理器:將小芯片設(shè)計(jì)進(jìn)行到底
從過去幾周英特爾在各類活動中的表述來看,特別是參考Hot Chips 2023和英特爾Innovation 2023大會上發(fā)布的消息,芯片巨頭的制程工藝路線圖及其服務(wù)器處理器設(shè)計(jì)思路將保持統(tǒng)一,共同為明年發(fā)布的至強(qiáng)SP系列CPU提供競爭力支撐。
當(dāng)然,英特爾與AMD Epyc芯片、Ampere Computing旗下各Arm產(chǎn)品,包括其他超大運(yùn)作模式基礎(chǔ)設(shè)施運(yùn)營商和云服務(wù)商的原研Arm服務(wù)器CPU之間仍有一定差距。但憑借著雄厚的渠道資源支持,英特爾仍有望以無所不達(dá)的銷售網(wǎng)絡(luò)和對舊有制程工藝的極限壓榨取得商業(yè)上的成功。至少在特定應(yīng)用負(fù)載之上,英特爾家的CPU仍保持著技術(shù)與經(jīng)濟(jì)的雙重優(yōu)勢。
但如今英特爾的地位已然動搖,所以必須設(shè)計(jì)好多戰(zhàn)線的競爭格局,憑借明年發(fā)布的高性能P核和高能效E核設(shè)計(jì)帶來更令人眼前一亮的成果。
當(dāng)然,這已經(jīng)不是英特爾第一次在服務(wù)器市場上參與多線作戰(zhàn)了,甚至AMD也不是。英特爾和AMD在之前的架構(gòu)中都曾經(jīng)歷過性能核與能效核并存的階段,只是這次情況更加特殊。英特爾當(dāng)初面向客戶端設(shè)備的凌動系列芯片擁有出色的512位AVX矢量引擎、ECC內(nèi)存清理機(jī)制、服務(wù)器級虛擬化等功能,并成為2015年針對高性能計(jì)算工作負(fù)載的“Knights”多核處理器產(chǎn)品線的基礎(chǔ)。而在AMD這邊,2016年1月推出的“Seattle”O(jiān)pteron A1100處理器希望挽回Opteron家族的頹勢,其上搭載的正是低功耗Arm Cortex-A57核心。此舉希望能將Opteron品牌打造成更強(qiáng)大、更高端的Arm服務(wù)器CPU產(chǎn)品線,甚至在設(shè)計(jì)上支持用EDA全局替換將Arm轉(zhuǎn)為X86核心。(雖然最終沒能用上。)
對于英特爾和AMD來說,這次的情況明顯有所不同。因?yàn)榇笮头?wù)器買家(即超大規(guī)模基礎(chǔ)設(shè)施運(yùn)營商和云服務(wù)商)及原始設(shè)備制造商(戴爾、HPE、聯(lián)想、浪潮、華為及思科等)都已向雙方提出明確要求:請?jiān)趩我环?wù)器平臺內(nèi)創(chuàng)新,不要搞跨服務(wù)器平臺創(chuàng)新。客戶們的需求很簡單,插槽之內(nèi)任你怎么折騰,但千萬別跨架構(gòu)。
正因如此,AMD才決定在今年推出第四代Epyc處理器。正常來講其代號應(yīng)該為“Genoa”,但此次卻多出了“Bergamo”和“Siena”等子代號,分別配備Zen 4性能核和Zen 4c能效核(二者最大的區(qū)別是核心的L3緩存容量)。英特爾這邊則計(jì)劃推出第五代至強(qiáng)SP,各版本同時支持能效E核和性能P核,且無需對插槽或平臺做任何調(diào)整。英特爾的策略就是維持兩種不同取向的核心,之后在構(gòu)建SKU棧時靈活組合以覆蓋更多負(fù)載需求。AMD和英特爾似乎都不想在單一插槽之內(nèi)混合搭配不同核心,這也可以理解。畢竟至少對現(xiàn)代數(shù)據(jù)中心的運(yùn)行需求來說,在機(jī)架層級做性能/能效混合已經(jīng)足夠,進(jìn)一步細(xì)分純屬勞民傷財(cái)。
在Hot Chips大會上,英特爾服務(wù)器芯片架構(gòu)師Chris Gianos(之前曾參與過安騰芯片和Digital Equipment公司多代處理器產(chǎn)品的研發(fā))談到了下一代至強(qiáng)SP的整體架構(gòu),并介紹了“Granite Rapids”性能核至強(qiáng)SP的某些功能特性。曾在惠普研發(fā)HP 9000和安騰處理器的現(xiàn)任英特爾芯片設(shè)計(jì)師Don Soltis則介紹了搭載能效E核的“Sierra Forest”至強(qiáng)SP處理器。

Gianos表示,這些設(shè)計(jì)中去掉了用于南橋I/O的外部獨(dú)立PCH芯片組。但我們也可以合理推測,PCH功能實(shí)際上是被加上PCI-Express、以太網(wǎng)和UltraPath互連(UPI),再配合各種控制器和加速器共同塞進(jìn)了兩個小芯片當(dāng)中。值得注意的是,英特爾第六代至強(qiáng)SP架構(gòu)的內(nèi)存控制器并非位于I/O芯片之上,而是位于核心加緩存復(fù)合體之上。
Gianos解釋道,“我們認(rèn)為把這些要素結(jié)合起來非常重要,因?yàn)檫@是個理想的優(yōu)化方向,在性能和計(jì)算密度方面都有積極意義。”
很明顯,為了進(jìn)一步充實(shí)第六代至強(qiáng)SP的SKU棧,英特爾可以向其中添加不同數(shù)量的I/O芯片和計(jì)算芯片,并根據(jù)相應(yīng)的價(jià)格設(shè)定和功率水平分別激活對應(yīng)配置。而且本周Innovation 2023大會也傳出消息,隨著288核Sierra Forest能效核版本的發(fā)布,英特爾能夠進(jìn)一步提升第六代至強(qiáng)SP的規(guī)格,將其“Advanced Platform”(AP版)產(chǎn)品的核心數(shù)量再增加一倍。整個思路跟2019年4月發(fā)布的“Cascade Lake”Advanced Platform至強(qiáng)處理器完全相同,當(dāng)時這款產(chǎn)品就是為了縮小與AMD在每插槽核心數(shù)量上的差距。目前我們還沒有看到Granite Rapids性能核版本的Advanced Platform雙倍核心版本,但只要英特爾愿意,相信完全可以做到。
Gianos還特意強(qiáng)調(diào),英特爾打造的是一套模塊化服務(wù)器芯片架構(gòu),能夠在插槽內(nèi)靈活調(diào)整不同要素的比例,借此滿足更廣泛的用例和客戶場景。
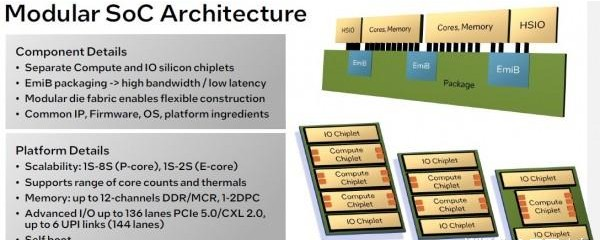
英特爾正使用其2.5D嵌入式多芯片互連橋(EMIB)這項(xiàng)多芯片封裝技術(shù)將小芯片粘合起來。EMIB是英特爾針對臺積電晶圓基板上芯片(CoWoS)2.5D封裝技術(shù)的回應(yīng)之舉,后者已經(jīng)被廣泛應(yīng)用于GPU及各類加速器芯片。展望未來,英特爾可以使用其Foveros 3D芯片封裝為至強(qiáng)SP設(shè)計(jì)添加垂直L3緩存擴(kuò)展,思路與AMD在其Milan-X和Genoa-X處理器上使用的3D-Vache非常相似。
上圖所示,為英特爾在第六代至強(qiáng)SP芯片中可能提供的不同選項(xiàng),但我們猜測Granite Rapids和Sierra Forest各自只能使用其中部分選項(xiàng),因?yàn)槠銼KU棧也是分別針對不同產(chǎn)品線設(shè)計(jì)而成。Gianos表示,總體來講,英特爾可以使用最右下設(shè)計(jì)提供低至個位數(shù)核心加極高I/O容量的至強(qiáng)SP芯片,也可以根據(jù)客戶需求在居左的小芯片設(shè)計(jì)中將核心數(shù)量增加至三位數(shù)。
能效核系統(tǒng)將支持單/雙插槽,就是說I/O芯片中的某些UPI鏈路將被禁用;而性能核系統(tǒng)將提供單、雙、四、八插槽,且激活的UPI鏈路數(shù)量也相應(yīng)增加。每個核心小芯片將擁有4個內(nèi)存控制器,可支持DDR 5或MCR內(nèi)存(后文將詳細(xì)介紹),因此最高規(guī)格的第六代至強(qiáng)SP將擁有12個內(nèi)存控制器為芯片提供服務(wù),每通道可對應(yīng)單/雙DIMM,具體取決于客戶對容量和帶寬的需求。這兩個I/O芯片可提供144條UPI互連通道(共6個端口,即每I/O芯片3個端口)和136條PCI-Express 5.0互連通道(即每I/O芯片68條通道)。我們推測,這些PCI-Express通道中將有半數(shù)能夠支持CXL 2.0內(nèi)存協(xié)議。但英特爾最終也有可能選擇全部兼容CXL 2.0,這就屬于意外驚喜了。
根據(jù)Gianos的解釋,英特爾還打算在第六代至強(qiáng)SP上打造所謂“虛擬單體芯片”,將至強(qiáng)E5/E7和至強(qiáng)SP處理器已經(jīng)使用十余年的片上網(wǎng)格互連擴(kuò)展至可跨EMIB互連。Gianos表示,任意小芯片中的任意元件都可以與該擴(kuò)展網(wǎng)格上的任意其他元件進(jìn)行通信,類似于經(jīng)典單體芯片設(shè)計(jì)。此外,連接芯片組的EMIB邊界將提供超1 TB/秒帶寬,以確保整個網(wǎng)格體系能夠快速、順暢互連互通。
Gianos補(bǔ)充稱,在Granite Rapids設(shè)計(jì)中,高端SKU將有“超0.5 GB”的末極緩存。英特爾也證實(shí),他們會在小芯片級別上建立sub-NUMA集群,通過這一默認(rèn)模式跨小芯片分配工作負(fù)載并提供內(nèi)存/計(jì)算局部性。
下圖所示,為第六代至強(qiáng)SP的計(jì)算芯片架構(gòu),這里以Granite Rapids性能核版本為例:
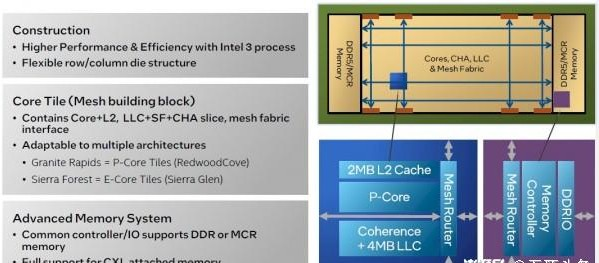
我們知道,采用三顆小芯片的全尺寸能效核Sierra Forest在單一封裝中最多可提供144個核心。每個核心塊配備3 MB的LLC緩存。根據(jù)Soltis的介紹,每個核心塊中容納4個能效核,相當(dāng)于每個小芯片對應(yīng)48個核心、折合12個核心塊。此外,每個小芯片擁有36 MB共享L3緩存,因此144核三芯片網(wǎng)格共有108 MB共享L3緩存。包含4個能效核的單一核心塊擁有4 MB L2緩存,每個小芯片都有12個核心塊,因此每個小芯片擁有48 MB L2緩存,每個Sierra Forest整體封裝擁有144 MB L2緩存(不到AP版的2倍)。但從速度測試來看達(dá)不到這個水平,所以此處推測可能有誤。
在性能核這邊,計(jì)算方式則略有不同。每個核心擁有4 MB L3緩存和專用的2 MB L2緩存。所以Granite Rapids的實(shí)質(zhì),就相當(dāng)于把Sierra Forest中的4顆能效核及其緩存取出,再換上相應(yīng)的性能核及其緩存。憑借超過512 MB的L3緩存,理論上Granite Rapids的非AP版本在每個插槽上可提供超128個核心。性能核的2個線程都支持HyperThreading超線程功能、擁有1個AVX-512矢量單元和1個AMX矩陣單元。從配置上來看,Granite Rapids版的發(fā)熱量無疑會高于Sierra Forest。
順帶一提,128核這個數(shù)字跟Soltis在演講中的表述有所出入:“從概念上講,我們就是直接把性能核替換成了能效核。除此之外,其他所有設(shè)計(jì)都是完全相同的,后續(xù)我們還會推出其他基本相同設(shè)計(jì)的芯片。”
如果真是如此,那么Granite Rapids最多也只能容納36個核心,這個數(shù)量肯定不夠用。所以推測Granite Rapids的最高配能容納3個核心塊,而Sierra Forest最多只能容納2個核心塊。
如果以上判斷正確,那么每個能效核小芯片可能承載80個核心——也許是在4個核心上采用10 x 2的網(wǎng)格設(shè)計(jì)。但考慮到該芯片的實(shí)際利用率只有90%,那么活動核心就是72個,對應(yīng)的是18個活動能效核心塊、54 MB共享L3緩存和72 MB L2緩存。這樣2個小芯片就能容納36個能效核心塊,對應(yīng)144個核心、108 MB共享L3緩存和144 MB L2緩存。
現(xiàn)在我們?nèi)?個這種小芯片,把能效核換成搭載4 MB共享L3緩存和2 MB L2緩存的性能核。這樣考慮單一核心塊上完整搭載20個核心的情況,也就是60個核心。我們假設(shè)英特爾用盡了所有針腳、打造出一款全部核心都能正常工作的版本,那其核心數(shù)量也仍然有限。除非英特爾能想辦法把這個數(shù)字再翻倍至120核,否則我們實(shí)在想象不出來哪里還有設(shè)計(jì)AP版的空間。
憑著直覺,我們認(rèn)為普版Granite Rapids對應(yīng)的可能是72核心加288 MB L3緩存,就是說Granite Rapids的AP版將倍增至144核心加576 MB L3緩存——而且這一切只能分布在3個小芯片上。這倒是符合Gianos在演講中提到的“超過512 GB的LLC”。按這個結(jié)果來倒推,就是說英特爾會設(shè)計(jì)一款能效核小芯片,它的網(wǎng)格中可能容納84個核心;再結(jié)合英特爾關(guān)于Sierra Forest的介紹,在85%的良品率下,其實(shí)際可用核心為72個。如果說Sierra Forest確實(shí)只能容納2個計(jì)算小芯片,那……
不說了,這里有太多的假設(shè)和猜測,咱們至此為止。
Soltis提到,Sierra Forest也將提供多種變體,比如只激活一半的核心。所以有些版本雖然出廠時有72個核心,但卻只能提供72個線程,不過也許其時鐘速率會更高一點(diǎn)、高每個線程都稍強(qiáng)勁些。
在被問及性能核跟能效核該如何比較時,GIanos表示其實(shí)二者之間的差異并沒有固定的比例。但基本可以確定,能效核心的時鐘速率應(yīng)該更低,而且性能核的單線程性能應(yīng)該在能效核的2倍以上。但具體再高出多少就很難說,估計(jì)可能在20%到25%的水平;再考慮到性能核上搭載的AVX-512和AMX單元,其發(fā)熱量應(yīng)該也相應(yīng)高出20%到25%。但據(jù)我們所知,通過剝離掉這些額外單元、并在能效核中使用兩個更小的128位AVX矢量單元,英特爾沒準(zhǔn)可以在相同的發(fā)熱量之下讓能效核獲得高于性能核的時鐘速率。
但實(shí)際情況究竟如何,恐怕只有時間能給出答案。
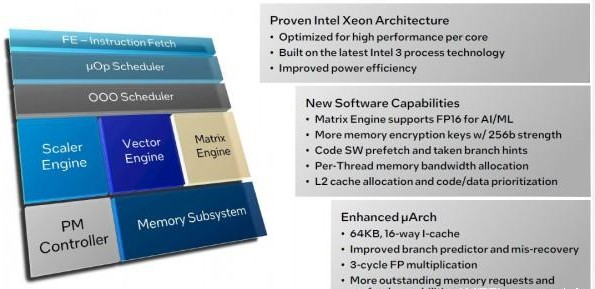
下面來看性能P核的介紹圖表:
再看能效E核的介紹圖表:

Sierra Forest和Granite Rapids都將采用Intel 3制程工藝,有人說其基本對應(yīng)臺積電的5納米工藝,也有人認(rèn)為其已經(jīng)更接近3納米工藝。但最重要的是,Intel 3肯定不是7納米或者10納米工藝,其制程精度已經(jīng)相當(dāng)領(lǐng)先,足夠讓英特爾的架構(gòu)優(yōu)勢發(fā)揮出實(shí)際效果。
性能核和能效核都采用64 KB L1指令緩存,這對保持核心的高負(fù)荷運(yùn)轉(zhuǎn)非常重要。我們認(rèn)為L1指令緩存越大,就能更好地掩蓋其小芯片、而非單體芯片設(shè)計(jì)所帶來的延遲。緩存為王,此言非虛……
Soltis還深入介紹了能效核架構(gòu)。這是一種不同的架構(gòu),在英特爾內(nèi)部的代號為“Sierra Glen”。(這一代性能核的代號為「Redwood Cove」,是對已經(jīng)上市的第四代「Sapphire Rapids」至強(qiáng)SP處理器中使用的「Golden Cove」性能核的升級產(chǎn)物。)其正面布局如下所示:

再來看指令引擎單元的構(gòu)成:

執(zhí)行單元如下所示:

整數(shù)和矢量性能間也有合理的平衡點(diǎn),Soltis表示能效核中的AVX單元(并非AVX-512或者AVX-10)將支持INT8、BF16和FP16格式,但沒有提及是否支持FP32和FP64。
再來看能效核的背面布局,包括32 KB L1數(shù)據(jù)緩存和4 MB L2緩存,后者由同一核心塊內(nèi)的雙/四能效核心共享:

Granite Rapids和Sierra Forest的I/O芯片完全相同,因此二者才能共享同樣的設(shè)計(jì)平臺。
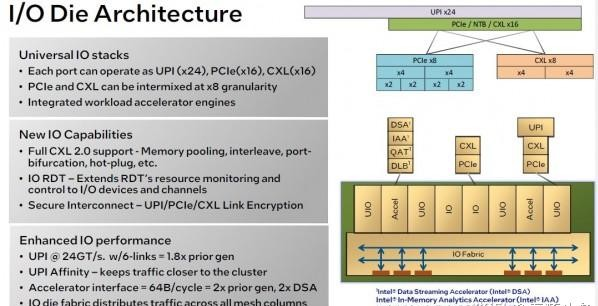
英特爾在第六代至強(qiáng)SP上使用的UPI鏈接速度稍慢,但帶寬也略微增大,這明顯比之前的至強(qiáng)SP有了更好的NUMA性能平衡。片上加速器的接口帶寬也迎來倍增,可借此提高運(yùn)行效率。
推薦產(chǎn)品+


相關(guān)推薦
-
開發(fā)方案")
-
PM2.5檢測儀MCU單片機(jī)開發(fā)方案
空氣質(zhì)量的確保對人類健康至關(guān)重要。在現(xiàn)代工業(yè)化進(jìn)程中,各類污染物排放導(dǎo)致了空氣質(zhì)量的下降,對人們的健康帶來嚴(yán)重威脅。其中,PM2.5顆粒物是空氣污染的主要成分之一,其直徑在2.5微米以下使其易進(jìn)入人體呼吸道,對人體健康影響極大。因此,研發(fā)一種基于單片機(jī)的PM2.5檢測儀成為了當(dāng)今關(guān)注的焦點(diǎn)之一。本文將詳細(xì)介紹基于單片機(jī)的PM2.5檢測儀的設(shè)計(jì)原理及實(shí)施過程。一、設(shè)計(jì)原理PM2.5測量原理PM2.5是指空氣中直徑小于等于2.5微米的顆粒物。因?yàn)槠淞叫。讘腋≡诳諝庵校M(jìn)入人體呼吸道后會對健康產(chǎn)生嚴(yán)重影響。目前用于測量PM2.5的方法主要有激光散射法和電動力學(xué)方法。本設(shè)計(jì)采用電動力學(xué)方法進(jìn)行PM2.5測量。電動力學(xué)方法電動力學(xué)方法是通過測量顆粒物在電場中的運(yùn)動來判斷其濃度。一般來說,通過將空氣樣本中的顆粒物帶電,并在電場中加速,利用帶電顆粒物受力的大小和方向來測量其濃度。本設(shè)計(jì)中,我們將使用激光散射法與電動力學(xué)方法相結(jié)合,通過測量散射光強(qiáng)度來得到顆粒物濃度。二、設(shè)計(jì)過程硬件設(shè)計(jì)(1)傳感器模塊PM2.5檢測儀的關(guān)鍵部件是傳感器模塊。傳感器模塊一般包括激光散射模塊和電場生成模塊。激光散射模塊負(fù)責(zé)發(fā)射激光束并測量散射光的強(qiáng)度。電場生成模塊則負(fù)責(zé)生成恰當(dāng)?shù)碾妶鲆詼y定帶電顆粒物的運(yùn)動狀態(tài)。(2)光電檢測模塊光電檢測模塊負(fù)責(zé)接收激光散射后的光信號,并將其轉(zhuǎn)化為電信號。然后,通過放大和濾波等環(huán)節(jié)來得到有效的光電信號。(3)單片機(jī)模塊單片機(jī)模塊用于控制整個系統(tǒng)的運(yùn)行,并將測量結(jié)果顯示在LCD屏幕上。可以選擇常用的單片機(jī)芯片,如Arduino。軟件設(shè)計(jì)在軟件設(shè)計(jì)過程中,需要編寫相應(yīng)的程序來實(shí)現(xiàn)PM2.5的測量和數(shù)據(jù)處理。主要包括以下幾個方面:(1)激光散射光信號處理需要編寫程序?qū)す馍⑸涔庑盘栠M(jìn)行處理,包括濾波、放大等操作,以提高光電傳感器的靈敏度。(2)電場生成與控制編寫程序控制電場的生成和控制,通過電場的大小和方向來確定帶電顆粒物的運(yùn)動狀態(tài)。(3)測量結(jié)果顯示編寫程序?qū)y量結(jié)果以數(shù)字或圖形顯示在LCD屏幕上,方便用戶觀察和分析。為了保證PM2.5檢測儀的準(zhǔn)確度和可靠性,需要進(jìn)行相應(yīng)的性能評估。可以通過與其他商用PM2.5檢測儀進(jìn)行對比測試來評估檢測儀的準(zhǔn)確性,同時進(jìn)行長時間連續(xù)測量來評估其穩(wěn)定性。基于單片機(jī)的PM2.5檢測儀可以應(yīng)用于室內(nèi)和室外環(huán)境中,對PM2.5污染進(jìn)行監(jiān)測和預(yù)警。可以廣泛應(yīng)用于居民樓、辦公室、學(xué)校等場所,幫助人們及時了解空氣質(zhì)量狀況,并采取相應(yīng)的措施,保護(hù)健康。結(jié)論:本文詳細(xì)介紹了基于單片機(jī)的PM2.5檢測儀的設(shè)計(jì)原理和實(shí)施過程。該檢測儀利用激光散射法和電動力學(xué)方法進(jìn)行測量,通過單片機(jī)控制實(shí)現(xiàn)對PM2.5的準(zhǔn)確測量并顯示結(jié)果。該設(shè)計(jì)具有一定的應(yīng)用前景,可以在居民樓、辦公室、學(xué)校等場所用于監(jiān)測和預(yù)警空氣質(zhì)量,幫助人們保護(hù)健康。隨著技術(shù)的不斷進(jìn)步,基于單片機(jī)的PM2.5檢測儀有望得到進(jìn)一步改進(jìn)和優(yōu)化,成為實(shí)用的環(huán)境監(jiān)測儀器。
-

-
基于武漢芯源CW32的無刷水泵方案——武漢芯源代理商永芯易科技
無刷電機(jī)是一種新型的電機(jī),其特點(diǎn)是不需要刷子進(jìn)行轉(zhuǎn)子與定子的電接觸。相比于傳統(tǒng)電機(jī),無刷電機(jī)具有更高的效率、更小的體積和更長的壽命。本文將從工作原理、組成結(jié)構(gòu)和與傳統(tǒng)電機(jī)的區(qū)別三個方面來詳細(xì)介紹無刷電機(jī)的特點(diǎn)。圖1網(wǎng)上的無刷電機(jī)首先,無刷電機(jī)的工作原理是基于電磁感應(yīng)和電子控制。無刷電機(jī)的轉(zhuǎn)子是由永磁體組成,定子則是由線圈組成。當(dāng)電流通過定子線圈時,會產(chǎn)生一個磁場,這個磁場會與轉(zhuǎn)子永磁體的磁場相互作用,從而使轉(zhuǎn)子開始旋轉(zhuǎn)。在轉(zhuǎn)子旋轉(zhuǎn)的同時,電子控制器會監(jiān)測轉(zhuǎn)子的位置和速度,并控制定子線圈的電流,從而保證電機(jī)的穩(wěn)定運(yùn)行。其次,無刷電機(jī)的組成結(jié)構(gòu)也有所不同。傳統(tǒng)電機(jī)的轉(zhuǎn)子是由電刷和電極組成,而無刷電機(jī)的轉(zhuǎn)子則是由永磁體和磁傳感器組成。此外,無刷電機(jī)還需要電子控制器來控制電流和轉(zhuǎn)子的位置和速度。這些特殊的組成結(jié)構(gòu)使得無刷電機(jī)具有更高的效率和更長的壽命。最后,無刷電機(jī)與傳統(tǒng)電機(jī)的區(qū)別在于其效率、體積和壽命。無刷電機(jī)的效率比傳統(tǒng)電機(jī)高出約10%至20%,這是由于無刷電機(jī)不需要電刷進(jìn)行轉(zhuǎn)子與定子的電接觸,從而減少了摩擦和能量損失。此外,無刷電機(jī)的體積也比傳統(tǒng)電機(jī)小,這是由于無刷電機(jī)的轉(zhuǎn)子不需要電刷,從而減少了轉(zhuǎn)子的體積。最后,無刷電機(jī)的壽命也比傳統(tǒng)電機(jī)長,這是由于無刷電機(jī)不需要電刷進(jìn)行電接觸,從而減少了電刷的磨損和壽命。圖2無刷直流電機(jī)結(jié)構(gòu)示意圖綜上所述,無刷電機(jī)具有高效、小巧和長壽命等特點(diǎn)。隨著無刷電機(jī)技術(shù)的不斷發(fā)展,無刷電機(jī)將在越來越多的領(lǐng)域得到應(yīng)用,如電動汽車、無人機(jī)、機(jī)器人等。所以在各個行業(yè)運(yùn)用無刷電機(jī)會越來越多,本次會用基于CW32芯片之下開發(fā)一款可以應(yīng)用于大多數(shù)場景的一款水泵。現(xiàn)在對于水泵要求越來越高,所以我們改進(jìn)水泵的工作模式,使水泵工作于最優(yōu)工作點(diǎn),降低功耗,就能實(shí)現(xiàn)水泵系統(tǒng)的節(jié)能,即節(jié)約電能和水能,給企業(yè)帶來效益,同時也能提升競爭力。在系統(tǒng)中,水泵的運(yùn)行是靠無刷直流電機(jī)來帶動的。本課題研究的目的是設(shè)計(jì)一套基于CW32的無位置傳感器無刷直流電機(jī)控制系統(tǒng)(方波控制模式),既可以改進(jìn)水泵的工作模式,使水泵工作點(diǎn)最優(yōu);又可以使水泵電機(jī)結(jié)構(gòu)簡單,控制方式更為靈活。以此將整個系統(tǒng)加入各個不同場景中,讓CW32低功耗的優(yōu)點(diǎn),能讓水泵共更加節(jié)能,高效。本文設(shè)計(jì)一個小型水泵循環(huán)控制系統(tǒng),該系統(tǒng)中帶動水泵運(yùn)行的電機(jī)的額定電壓是48V,額定功率為500W。控制系統(tǒng)是基于CW32處理器,采用反電勢過零檢測方法對轉(zhuǎn)子位置進(jìn)行檢測,從而實(shí)現(xiàn)對電機(jī)的換向控制。水泵控制系統(tǒng)中,采用無位置傳感器無刷直流電機(jī)來帶動水泵運(yùn)行,不但縮小了水泵體積,而且增強(qiáng)了水泵運(yùn)行時電機(jī)的抗干擾性和穩(wěn)定可靠性。使水泵工作于最優(yōu)工作點(diǎn),盡可能使運(yùn)行功率降低,改變了水泵一直滿功率運(yùn)行的狀況,降低了功耗,實(shí)現(xiàn)了水泵系統(tǒng)的節(jié)能。
 哦! 它是空的。
哦! 它是空的。